
In the field of Industrial IoT, standards are playing an increasingly important role in ensuring interoperability between devices from different manufacturers. One such standard is Sparkplug B. This aims to define communication in MQTT-based networks. The advantages and disadvantages of Sparkplug B in MQTT networks are discussed in the following article.
What is Sparkplug B?
Sparkplug B is an open standard of the Eclipse Foundation and comprises one specification. The emergence of Sparkplug B can be traced back to MQTT’s conscious decision not to define any standards for the structuring of MQTT messages. This openness has made the protocol very popular in the IoT world. However, this flexibility also leads to problems, especially when it comes to interoperability between different systems. Difficulties can arise when different devices and applications need to communicate seamlessly via MQTT. Sparkplug closes precisely this gap with its focus on SCADA environments. To this end, the standard defines uniform data formatting and uniform state management within MQTT.
An evolution of Sparkplug A: Sparkplug B builds on the principles of Sparkplug A. Sparkplug A is an earlier initiative to extend the MQTT standard, but it did not catch on. Sparkplug B further developed the concepts and objectives of Sparkplug A and transformed them into a robust specification. This addresses the requirements of modern infrastructures and has thus found greater acceptance in the industry.
Terminology and architecture
Sparkplug defines a clear terminology and architecture for the organization of messages to ensure the unambiguity and efficiency of data transmission.

Sparkplug’s architecture consists of several key components:
- MQTT Server (Broker) as the core of the Sparkplug architecture. This serves as a node for message transmission between edge nodes and the primary host application.
- Edge nodes are located at the edge of the network (e.g. IPCs, gateways, PLCs). These collect data from sensors and actuators and forward it to the broker.
- Edge deviceas a physical device that captures (sensor) or generates (actuator) data.
- Primary host application: The central application that processes the data. For example, a SCADA system that is responsible for monitoring, controlling and optimizing production processes.
Sparkplug B vs. MQTT
To illustrate the added value of Sparkplug, Level 0 to Level 5 of the “Data Access Model” (source: Matthew Parris) are shown below. The Data Access Model serves as a framework for data access. It outlines the essential levels that are crucial for interoperability between data sources and consumers in an industrial context. Undefined levels promote flexibility at the expense of greater integration effort, as each implementation must be interpreted and integrated individually. Sparkplug B complements the MQTT standard as follows.

Level 2 – Mappings
Specific protocol mappings are defined at this level. These determine how data is structured and transmitted within the selected communication protocol. Sparkplug defines a specific mapping for MQTT messages, including the use of topics and the structure of the payload. This includes conventions for topic namespaces that allow the type of message (e.g. DDATA for device messages) to be identified and routed efficiently.
Level 3 – Encoding
This level deals with the way in which data is encoded for transmission over the network. This includes the choice of data format, which defines both the efficiency of transmission and compatibility between different systems. The encoding directly influences the size and thus the transmission speed of the messages as well as the required processing power on the receiver side. Sparkplug B uses Protobuf for encoding messages. Protobuf is a binary format from Google that was developed for the serialization of structured data. This allows messages to be processed quickly and transmitted effectively over networks with potentially limited bandwidth. You can find more information about Protobuf here.
Level 4 – Values
This level determines which data types are transferred. A clear specification of data types is essential for the correct interpretation and use of data by different systems. Sparkplug B defines a total of 19 data types and includes both simple data types such as numbers and texts as well as complex structures and user-defined types.
Level 5 – Objects
This level defines data models and schemas, i.e. how data is organized as objects, including their attributes and methods. This is particularly relevant for the application logic. Sparkplug B does not define a standard at this level. Detailed information on data modeling can be found here.
Sparkplug B Topic Namespace
The standard defines the topic namespace and thus a clear MQTT topic structure as follows: spBv1.0/group_id/message_type/edge_node_id/[device_id]. This setup enables the identification and grouping of data streams in an IIoT network and consists of the following components:
- spBv1.0 signals the use of Sparkplug encoding.
- Group ID allows edge nodes to be grouped logically (e.g. according to geographical locations or functional units).
- Message Type distinguishes between different types of MQTT messages (e.g. DDATA for device messages)
- Edge Node ID and Device ID for a unique identifier for edge devices, which enables direct communication and clear assignment of data streams.
A practical example of a manufacturing company with a site in Prague would be the structure: spBv1.0/ExampleCompany:Prague/DDATA/MillingArea1:Line1/Cell1
Message Types
Sparkplug defines different types of MQTT messages (message types), which are specified in the topic namespace and fulfill special functions:
- NBIRTH – Birth certificate for Sparkplug Edge Nodes. Is used to announce the initial registration of an Edge Node in the network and to transmit its metadata.
- NDEATH – Death certificate for Sparkplug Edge Nodes. Used to inform the network about the orderly shutdown or unexpected failure of an Edge Node.
- DBIRTH – Birth certificate for devices. Similar to NBIRTH, but for individual devices to report their presence and configuration to the network.
- DDEATH – Death certificate for devices. Informs the network when a device is shut down, whether this is due to a planned shutdown or an error.
- NDATA – Edge Node data message. Transmits the actual operating data from an edge node, for example measured values or status information.
- DDATA – Device data message. Transmits operating data from individual devices, such as measured values or sensor data, to the network.
- NCMD – Edge Node command message. Enables the transmission of control commands to an edge node in order to trigger certain actions or change configurations.
- DCMD – Device command message. Wie NCMD, jedoch speziell für das Senden von Befehlen an einzelne Geräte konzipiert.
- STATE – Sparkplug Host Application state message. Transmits the status of the Sparkplug Host Application, including availability and health status, to the network.
Sparkplug B Payload
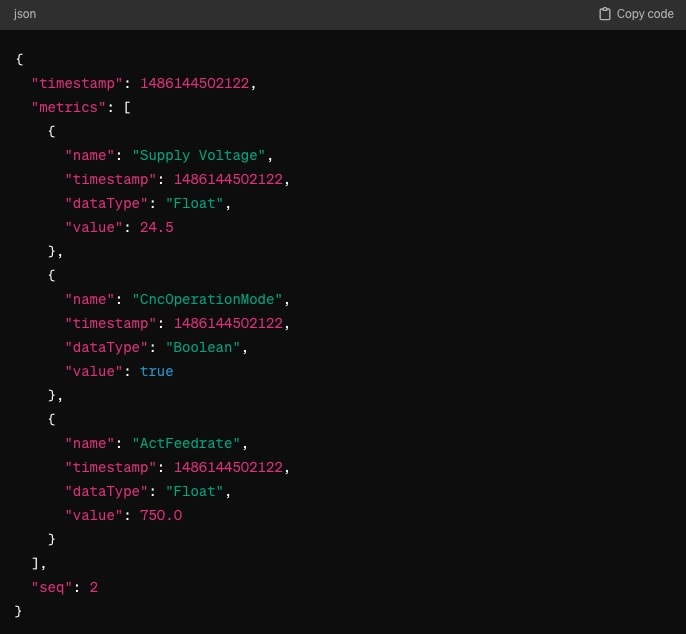
The Sparkplug payloads use Google Protocol Buffers to provide a compact method of data transmission. These payloads contain metrics, metadata and status information that make it possible to provide updates on the status of devices and sensors. Each payload follows a defined structure that standardizes the reading and writing of data. The following example shows an NDATA message that is published in the spBv1.0/ExampleCompany:Prague/DDATA/MillingArea1:Line1/Cell1. This configuration causes the host application to update the value of the Supply Voltage, CNCOperationMode and ActFeedrate.
Pros and cons of Sparkplug B
Sparkplug B presents both significant advantages and challenges in an industrial context that need to be carefully weighed up:
Pros
- Payload definition and interoperability: By using consistently interpreted data types across the MQTT ecosystem, Sparkplug B leads to higher interoperability.
- Session Management: It provides a standard for managing the session state of all connected components, which facilitates coordination and synchronization.
- Defined topic naming: By structuring the MQTT topic namespace, Sparkplug promotes clarity and consistency in communication.
Cons
- Complexity: The reliance on ProtoBuf may be familiar to IT professionals, but can present additional complexity for OT professionals who are less familiar with this coding mechanism.
- Bandwidth savings vs. complexity: For manufacturing systems connected with Ethernet cables, the bandwidth savings that Sparkplug B brings may not justify the increased complexity.
- Primary application: The concept of the primary application can lead to problems. If the primary application fails, machines stop the data transfer. This makes little sense, especially in the context of a Unified Namespace (UNS).
- Limitations in the topic elements: Sparkplug limits the number of topic elements. This restricts scalability and compatibility with complex organizational structures such as ISA-95. Restrictions affect the use of wildcards (e.g. no subscription to all messages of a production line) and the possibility of selectively subscribing to subsets of the data payload.
- QoS 0: Sparkplug B forces all data transmissions to Quality-of-Service (QoS) level 0. At this QoS level, the broker only transmits the messages according to the “at most once” principle. This means that messages can be lost (further information on QoS can be found here). This considerably limits the reliability of data transmission and makes Sparkplug B unsuitable for many use-cases.
- No retained messages: Sparkplug B does not allow the use of the retain flag for data or birth messages. This means that the “current state” cannot be saved in the broker, which makes Sparkplug B unsuitable for many use-cases (further information on retained messages can be found here).
Conclusion
Sparkplug B addresses key challenges in scaling an MQTT-based infrastructure in industrial IoT environments. The definition of a standard for topic namespace, payloads and session management can bring significant benefits, especially in SCADA environments (scenario: n:1 integration). However, the standard also has significant limitations, including the deviation from the widely used ISA-95 model, the dependency on ProtoBuf and restrictions on the topic elements. These lead to problems, particularly in the context of a Unified Namepace (UNS) architecture (scenario: n:m integration).
Therefore, companies should carefully consider their specific requirements, taking into account factors such as the existing organizational structure, the expertise of their employees and the use-case (n:1 vs. n:m integration scenarios).
