
Im Bereich des Industrial IoT spielen Standards eine immer entscheidendere Rolle, um die Interoperabilität zwischen Geräten verschiedener Hersteller zu gewährleisten. Ein solcher Standard ist Sparkplug B. Dieser zielt darauf ab, die Kommunikation in MQTT-basierten Netzwerken zu definieren. Welche Vor- und Nachteile Sparkplug B mit sich bringt, wird in folgendem Artikel beleuchtet.
Was ist Sparkplug B?
Sparkplug B ist ein offener Standard der Eclipse Foundation. Die zum Zeitpunkt dieses Artikels aktuelle Version ist Sparkplug 3.0, veröffentlicht im November 2022 als erste offizielle Eclipse Specification der Eclipse Sparkplug Working Group. Die Entstehung von Sparkplug B ist auf die bewusste Entscheidung von MQTT zurückführen, keine Standards für die Strukturierung von MQTT Nachrichten zu definieren. Durch diese Offenheit hat das Protokoll zwar große Beliebtheit in der IoT-Welt erlangt. Allerdings führt diese Flexibilität auch zu Problemen, insbesondere bei der Interoperabilität zwischen verschiedenen Systemen. Dabei können Schwierigkeiten entstehen, wenn unterschiedliche Geräte und Anwendungen nahtlos über MQTT kommunizieren sollen. Genau diese Lücke schließt Sparkplug mit dem Fokus auf SCADA Umgebungen. Hierfür definiert der Standard eine einheitliche Datenformatierung und ein einheitliches State Management innerhalb von MQTT.
Eine Weiterentwicklung von Sparkplug A: Sparkplug B baut auf den Prinzipien von Sparkplug A auf. Sparkplug A ist eine frühere Initiative zur Erweiterung des MQTT Standards, die sich jedoch nicht durchgesetzt hat. Mit Sparkplug B wurden die Konzepte und Ziele von Sparkplug A weiterentwickelt und in eine robuste Spezifikation überführt. Diese adressiert Anforderungen moderner Infrastrukturen und hat so eine größere Akzeptanz in der Industrie gefunden.
Terminologie und Architektur
Sparkplug definiert eine klare Terminologie und Architektur für die Organisation von Nachrichten, um die Eindeutigkeit und Effizienz der Datenübertragung zu gewährleisten.

Dabei besteht die Architektur von Sparkplug aus mehreren Schlüsselkomponenten:
- MQTT Server (Broker) als Kernstück der Sparkplug Architektur. Dieser dient als Knotenpunkt für die Nachrichtenübertragung zwischen Edge Nodes und der Primary Host Application.
- Edge Nodes befinden sich am Rand des Netzwerks (z.B. IPCs, Gateways, PLCs). Diese sammeln Daten von Sensoren und Aktuatoren und leiten sie an den Broker weiter.
- Edge Device als physisches Gerät, das Daten erfasst (Sensor) oder erzeugt (Aktuator).
- Primary Host Application: Die zentrale Anwendung, die die Daten verarbeitet. Zum Beispiel ein SCADA System, welches für die Überwachung, Steuerung und Optimierung der Produktionsprozesse verantwortlich ist.
Sparkplug B vs. MQTT
Um den Mehrwert von Sparkplug zu verdeutlichen, ist im Folgenden Level 0 bis Level 5 des „Data Access Model“ (Quelle: Matthew Parris) dargestellt. Das Data Access Model dient hierbei als ein Rahmenwerk für den Datenzugriff. Es skizziert die wesentlichen Ebenen (Level), welche für die Interoperabilität zwischen Datenquellen und -konsumenten im industriellen Kontext entscheidend sind. Dabei begünstigen undefinierte Ebenen die Flexibilität auf Kosten eines höheren Integrationsaufwands, da jede Implementierung individuell interpretiert und integriert werden muss. Sparkplug B ergänzt den MQTT Standard wie folgt.

Level 2 – Mappings
Auf dieser Ebene werden spezifische Protokoll-Mappings definiert, die festlegen, wie Daten innerhalb eines Kommunikationsprotokolls strukturiert und übertragen werden. Während MQTT diese Ebene bewusst offenlässt, spezifiziert Sparkplug ein standardisiertes Mapping für MQTT-Nachrichten. Dazu gehören sowohl die Definition der Topic-Struktur als auch der Aufbau der Nutzdaten (Payload). Über festgelegte Topic-Konventionen lässt sich beispielsweise der Nachrichtentyp, etwa DDATA für Device-Daten, eindeutig identifizieren und effizient routen.
Level 3 – Encoding
Diese Ebene beschreibt, wie Daten für die Übertragung über das Netzwerk kodiert werden. Dazu gehört die Wahl des Datenformats, das sowohl die Effizienz der Übertragung als auch die Kompatibilität zwischen unterschiedlichen Systemen beeinflusst. Das Encoding wirkt sich direkt auf die Größe der Nachrichten, die Übertragungsgeschwindigkeit sowie den Verarbeitungsaufwand auf Empfängerseite aus. Während MQTT selbst keine Vorgaben für das Encoding macht, verwendet Sparkplug B Protobuf zur Kodierung der Nachrichten. Protobuf ist ein von Google entwickeltes binäres Format zur Serialisierung strukturierter Daten. Dadurch lassen sich Nachrichten kompakt darstellen, schnell verarbeiten und auch über Netzwerke mit begrenzter Bandbreite effizient übertragen. Weitere Informationen zu Protobuf finden Sie hier.
Level 4 – Values
Diese Ebene legt fest, welche Datentypen übertragen werden. Dabei ist eine klare Spezifikation von Datentypen essentiell für die korrekte Interpretation und Nutzung der Daten durch unterschiedliche Systeme. MQTT macht hierzu keine Vorgaben. Sparkplug B definiert in Summe 19 Datentypen und umfasst sowohl einfache Datentypen wie Zahlen und Texte als auch komplexe Strukturen und benutzerdefinierte Typen.
Level 5 – Objects
Diese Ebene definiert Datenmodelle und -schemata, d.h. wie Daten als Objekte organisiert sind, einschließlich ihrer Attribute und Methoden. Dies ist insbesondere für die Interpretation der Daten sowie die Anwendungslogik relevant. Weder MQTT noch Sparkplug B definieren auf dieser Ebene einen Standard. Datenmodelle und -schemata müssen folglich individuell oder auf Basis anderer Spezifikationen erstellt werden. Weitere Informationen zur Datenmodellierung finden Sie hier.
Sparkplug B Topic Namespace
Wie beschrieben, definiert der Standard den Topic Namespace auf Level 2 des Data Access Models und damit eine klare Struktur wie folgt: spBv1.0/group_id/message_type/edge_node_id/[device_id]. Dieser Aufbau ermöglicht die Identifizierung und Gruppierung von Datenströmen in einem IIoT-Netzwerk und besteht aus den folgenden Komponenten:
- spBv1.0 signalisiert den Einsatz des Sparkplug Encodings.
- Group ID ermöglicht es, Edge Nodes logisch zu gruppieren (z.B. nach geografischen Standorten oder funktionalen Einheiten).
- Message Type unterscheidet zwischen verschiedenen Arten von MQTT-Nachrichten (z.B. DDATA für Device Nachrichten)
- Edge Node ID und Device ID für eine eindeutige Identifikatoren für Edge-Geräte, was eine direkte Kommunikation und eindeutige Zuordnung von Datenströmen ermöglicht.
Ein praxisnahes Beispiel für ein produzierendes Unternehmen mit einem Standort in Prag wäre die Struktur: spBv1.0/ExampleCompany:Prague/DDATA/MillingArea1:Line1/Cell1
Art von Nachrichten (Message Types)
Neben dem Topic Namespace definiert Sparkplug verschiedene Arten von MQTT Nachrichten (Message Types), welche im Topic Namespace veröffentlicht werden und spezielle Funktionen erfüllen:
- NBIRTH – Birth certificate für Sparkplug Edge Nodes. Wird verwendet, um die Erstregistrierung eines Edge Nodes im Netzwerk anzukündigen und dessen Metadaten zu übermitteln.
- NDEATH – Death certificate für Sparkplug Edge Nodes. Dient dazu, das Netzwerk über das geordnete Herunterfahren oder einen unerwarteten Ausfall eines Edge Nodes zu informieren.
- DBIRTH – Birth certificate für Devices. Ähnlich wie NBIRTH, aber für einzelne Geräte, um deren Anwesenheit und Konfiguration dem Netzwerk zu melden.
- DDEATH – Death certificate für Devices. Informiert das Netzwerk über das Ausscheiden eines Geräts, sei es durch geplantes Herunterfahren oder einen Fehler.
- NDATA – Edge Node data message. Überträgt die tatsächlichen Betriebsdaten von einem Edge Node, beispielsweise Messwerte oder Zustandsinformationen.
- DDATA – Device data message. Übermittelt Betriebsdaten von einzelnen Geräten, wie Messwerte oder Sensordaten, an das Netzwerk.
- NCMD – Edge Node command message. Ermöglicht die Übertragung von Steuerbefehlen an einen Edge Node, um bestimmte Aktionen auszulösen oder Konfigurationen zu ändern.
- DCMD – Device command message. Wie NCMD, jedoch speziell für das Senden von Befehlen an einzelne Geräte konzipiert.
- STATE – Sparkplug Host Application state message. Übermittelt den Zustand der Sparkplug Host Application, einschließlich Verfügbarkeit und Gesundheitsstatus, an das Netzwerk.
Sparkplug B Payload
Wie beschrieben nutzen Sparkplug-Payloads Google Protocol Buffers, um eine kompakte Methode zur Datenübermittlung bereitzustellen. Diese Payloads beinhalten Metriken, Metadaten und Zustandsinformationen, die es ermöglichen, Updates über den Zustand von Geräten und Sensoren zu liefern. Dabei folgt jeder Payload einer definierten Struktur, die das Lesen und Schreiben von Daten standardisiert. In folgendem Beispiel ist eine NDATA-Nachricht dargestellt, welche im Topic spBv1.0/ExampleCompany:Prague/DDATA/MillingArea1:Line1/Cell1 veröffentlicht wird. Diese Konfiguration führt dazu, dass die Host-Applikation den Wert des Supply Voltage, CNCOperationMode und ActFeedrate aktualisiert.
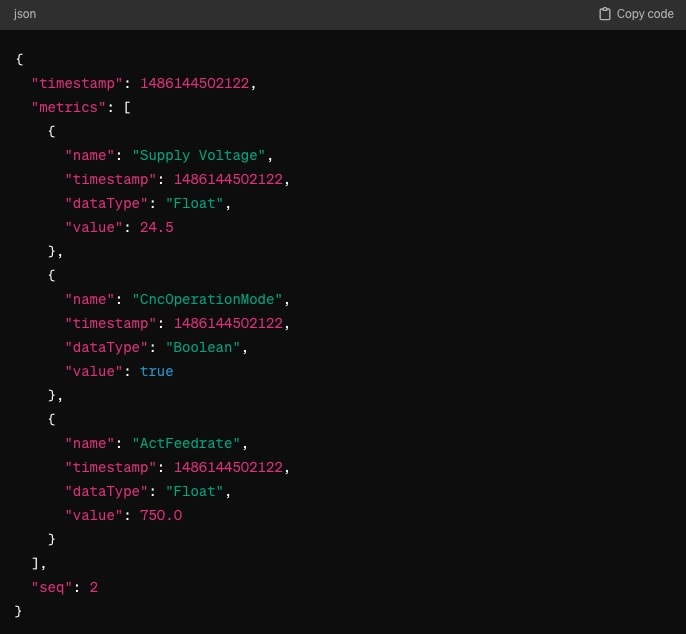
Aliases zur Payload-Optimierung: Ein wesentliches Effizienzmerkmal des Sparkplug-Payload-Modells sind sogenannte Aliases. In der initialen NBIRTH- oder DBIRTH-Nachricht wird jeder Metrik ein eindeutiger Name (z.B. „MillingArea1.Line1.Cell1.SupplyVoltage“) sowie ein numerischer Alias (z.B. 1234) zugewiesen. In allen nachfolgenden NDATA- bzw. DDATA-Nachrichten wird statt des vollständigen Metriknamens nur noch der Alias übertragen. Da Metriknamen in industriellen Anwendungen schnell 30 bis 100 Zeichen erreichen, reduziert dieser Mechanismus die effektive Payload-Größe um bis zu 80 Prozent und macht Sparkplug B insbesondere in bandbreitenlimitierten Netzen (Mobilfunk, Satellit, LPWAN) zu einer effizienten Wahl. Die Auflösung Alias → Metrikname erfolgt ausschließlich beim Konsumenten anhand der zuvor empfangenen Birth-Nachricht – fehlt diese, sind die Nutzdaten nicht interpretierbar (ein Grund mehr für die strenge Birth-/Death-Sequenzierung des Standards).
State Management: Sparkplug B vs. Plain MQTT
Ein zentraler Mehrwert von Sparkplug B gegenüber Plain MQTT liegt im standardisierten State Management. Während MQTT bewusst keine Aussage über den Zustand verbundener Clients trifft, definiert Sparkplug B einen klaren Lifecycle für Edge Nodes und Devices. Dies ist die Grundlage für deterministische SCADA-Anwendungen.
Lifecycle in Sparkplug B
Der Sparkplug-Lifecycle definiert die Abfolge von Zustands- und Datennachrichten eines Edge Nodes über die gesamte Verbindungsdauer – von der Anmeldung beim Broker bis zur geordneten oder unerwarteten Abmeldung. Fünf Bausteine bilden dabei das Fundament:

- Birth Messages (NBIRTH/DBIRTH): Beim Verbindungsaufbau eines Edge Nodes oder Devices wird eine Birth-Nachricht an den Broker gesendet. Diese enthält alle verfügbaren Metriken inklusive Datentypen, Aliasen und Initialwerten. Konsumenten erkennen damit unmittelbar, welche Daten verfügbar sind und in welchem Zustand sich das System befindet.
- Death Messages (NDEATH/DDEATH): Beim geordneten Abmelden oder einem unerwarteten Verbindungsabbruch wird eine Death-Nachricht ausgelöst.
- Last Will and Testament (LWT): Der Auslöser einer NDEATH ist nicht der Edge Node selbst, sondern der native MQTT-Mechanismus „Last Will and Testament“. Beim CONNECT hinterlegt der Edge Node eine vordefinierte NDEATH als LWT beim Broker. Bricht die Verbindung ungeordnet ab (Keepalive-Timeout, Netzwerkfehler, Stromausfall), veröffentlicht der Broker die NDEATH automatisch. Alle Konsumenten inkl. Primary Host erfahren so vom Ausfall, ohne aktiv pollen zu müssen. Sparkplug B standardisiert dabei Format und Bedeutung dieser Nachricht.
- Primary Application als Source of Truth: Die Primary Host Application überwacht alle Birth- und Death-Nachrichten und validiert kontinuierlich die Verfügbarkeit aller Knoten und Geräte. Bei Ausfällen kann sie Alarme, Failover-Mechanismen oder eine Re-Synchronisation auslösen.
- Sequence Numbers (seq, bdSeq): Zwei Sequenznummern sichern den deterministischen Wiederanlauf. Die seq (0–255, startet bei jeder NBIRTH bei 0) inkrementiert über alle operativen Nachrichten. Bricht die Reihenfolge ab, fordert der Primary Host per NCMD/REBIRTH einen Re-Sync an. Die bdSeq (64-Bit, pro Session inkrementiert) verhindert, dass eine verzögerte NDEATH aus einer alten Session auf die aktuelle angewendet wird. Beide kompensieren die fehlende Zustellgarantie unter QoS 0 auf Lifecycle-Ebene: Einzelne Werte können verlorengehen, der Gesamtzustand des Edge Nodes bleibt jedoch konsistent.
State Management in Plain MQTT
Plain MQTT bietet keine vergleichbare Funktionalität. Wer Statusinformationen benötigt, muss sie selbst modellieren:
- LWT-Nachrichten: MQTT unterstützt LWT als Basismechanismus, jedoch ohne standardisiertes Format. Inhalt und Interpretation müssen pro Projekt individuell festgelegt werden.
- Heartbeats / Keepalive: Clients können periodische Lebenszeichen senden, die andere Teilnehmer aktiv überwachen. Ohne LWT bleibt ein unerwarteter Ausfall allerdings unerkannt, bis das nächste Heartbeat-Intervall ausläuft.
- Custom Birth/Death über Retained Messages: Eigenimplementierungen (z.B. ein Retained-Topic „client/xyz/status“) sind möglich und in UNS-Architekturen verbreitet. Sie sind allerdings nicht out-of-the-box interoperabel zwischen Systemen unterschiedlicher Hersteller.
Vergleich State Management: Sparkplug B vs. Plain MQTT
Das standardisierte State Management ist einer der wichtigsten Mehrwerte von Sparkplug B gegenüber Plain MQTT – und gleichzeitig der Grund für seine Popularität in klassischen SCADA-Szenarien.
| Feature | Sparkplug B | Plain MQTT |
|---|---|---|
| Standardisierte Birth-/Death-Nachrichten | ✅ Ja | ❌ Nein (muss manuell umgesetzt werden) |
| Automatische Statusmeldung via LWT | ✅ Ja (NDEATH/DDEATH) | ✅ Ja, aber ohne Standardisierung |
| Zentralisierte State-Verwaltung | ✅ Ja (Primary Application) | ❌ Nein |
| Verfügbarkeitserkennung out-of-the-box | ✅ Ja | ❌ Nein, projektspezifisch |
| Hierarchischer Lifecycle (Node + Device) | ✅ Ja | ❌ Nein |
| Sequence Numbers gegen Datenverlust | ✅ Ja | ❌ Nein |
| Current State im Broker abrufbar | ❌ Nein (keine Retained Messages) | ✅ Ja (über Retained Messages) |
Die enge Bindung an die Primary Application und der Verzicht auf Retained Messages werden allerdings im UNS-Kontext zur Limitierung, wie der folgende Abschnitt zeigt.
Vor- und Nachteile von Sparkplug B
Sparkplug B präsentiert sowohl signifikante Vorteile als auch Herausforderungen im industriellen Kontext, die es sorgfältig abzuwägen gilt.
Vorteile
- Payload-Definition und Interoperabilität: Durch die Nutzung konsistent interpretierter Datentypen über das MQTT Ökosystem hinweg führt Sparkplug B zu einer höheren Interoperabilität.
- Session Management: Es bietet einen Standard für das Management des Sitzungszustands aller verbundenen Komponenten, was die Koordination und Synchronisation erleichtert.
- Definierte Topic-Namensgebung: Durch die Strukturierung des MQTT-Topic-Namensraums fördert Sparkplug Klarheit und Konsistenz in der Kommunikation.
Nachteile
- Komplexität: Die Abhängigkeit von ProtoBuf mag für IT-Professionals geläufig sein. Allerdings kann ProtoBuf für OT-Fachkräfte, die weniger mit diesem Encoding vertraut sind, eine zusätzliche Komplexität darstellen.
- Bandbreiteneinsparungen vs. Komplexität: Für mit Ethernet-Kabeln verbundene Fertigungssysteme mögen die Bandbreiteneinsparungen, die Sparkplug B mit sich bringt, die erhöhte Komplexität nicht rechtfertigen.
- Primary Application: Das Konzept der „Primary Application“ kann zu Problemen führen. Fällt die Primary Application aus, stoppen Maschinen die Datenübertragung. Dies ist insbesondere im Kontext eines Unified Namespace (UNS) wenig sinnvoll.
- Begrenzungen in den Topic-Elementen: Sparkplug begrenzt die Anzahl der Topic-Elemente. Dies schränkt die Skalierbarkeit und Kompatibilität mit komplexen Organisationsstrukturen wie ISA-95 ein. Einschränkungen betreffen die Nutzung von Wildcards (z. B. keine Subscription auf alle Nachrichten einer Produktionslinie) sowie die Möglichkeit zur selektiven Abonnierung von Teilinhalten der Data Payloads.
- QoS 0 für alle Daten- und Lifecycle-Nachrichten: Sparkplug B schreibt für die operativen Nachrichtentypen NBIRTH, DBIRTH, NDATA, DDATA, NDEATH und DDEATH zwingend QoS 0 vor. Bei diesem QoS-Level überträgt der Broker die Nachrichten nach dem Prinzip „at most once“. Nachrichten können also verloren gehen (weitere Infos zu QoS finden Sie hier). Lediglich STATE-Nachrichten der Primary Host Application werden mit QoS 1 übertragen, da die Verfügbarkeit der Host-Anwendung anderenfalls nicht zuverlässig signalisiert werden könnte.
- Keine Retained Messages: Sparkplug B erlaubt nicht die Verwendung des Retain-Flags für Daten- oder Birth Nachrichten. Dadurch kann der „Current State“ nicht im Broker gespeichert werden, was Sparkplug B für viele Use-Cases ungeeignet macht (weitere Infos zu Retained Messages finden Sie hier).
Wann ist Sparkplug B die richtige Wahl – und wann nicht?
Ob Sparkplug B die passende Wahl ist, hängt weniger vom Standard selbst als vielmehr von der angestrebten Zielarchitektur ab. Entscheidend ist die Frage, ob die Stärken – definiertes State Management, kompakte Payloads und Plug-and-Play-Verhalten in n:1-Architekturen – die strukturellen Einschränkungen überwiegen.
Wann Sparkplug B die richtige Wahl ist
Es gibt klar abgrenzbare Szenarien, in denen Sparkplug B nicht nur sinnvoll, sondern die bevorzugte Option ist:
- Klassische SCADA-Modernisierung (n:1 Integration): Wird ein bestehendes SCADA-System (z.B. Ignition, AVEVA, zenon) als zentrale Host-Anwendung betrieben und sollen Edge Nodes oder PLCs strukturiert angebunden werden, spielt Sparkplug B seine Stärken aus. Die definierten Birth-/Death-Zertifikate, Sequence Numbers und der konsistente Topic-Namespace reduzieren den Integrationsaufwand erheblich. In genau diesem Szenario ist der Standard ursprünglich entstanden. In diesem Fall wird die Datenarchitektur überwiegend von einem Anbieter bestimmt (Single-Vendor-Stack), der ISA-95-Konflikt entfällt weitgehend. Die starre Topic-Hierarchie ist dann eher Leitplanke als Limitation.
- Bandbreitenlimitierte und unzuverlässige Netze: In Szenarien mit Mobilfunk-, Satelliten- oder LPWAN-Anbindung sind Protobuf-Encoding und Aliase ein realer Vorteil. Dies ist typisch für Oil & Gas, Water/Wastewater, Windparks oder verteilte Anlagen. Die Bandbreiteneinsparungen rechtfertigen hier die zusätzliche Komplexität, da Datenvolumen direkt zu Betriebskosten und Latenz führen.
Wann Sparkplug B nicht die richtige Wahl ist
Genauso klar lassen sich Szenarien benennen, in denen die Einschränkungen des Standards überwiegen und eine Unified-Namespace-Architektur (UNS) vorteilhaft ist:
- Mehrere fachlich unabhängige Konsumenten (n:m Integration): Sollen MES, Historian, Analytics-Plattform, KI-Anwendungen und ERP parallel auf dieselben Datenströme zugreifen, wird das starre Primary-Host-Konzept zum Engpass. Jeder Konsument hat eigene Anforderungen an Granularität, Frequenz und Datenmodell – eine Anforderung, für die Sparkplug B konzeptionell nicht entworfen wurde.
- ISA-95-konforme Strukturierung: Wenn die Topic-Hierarchie die Ebenen Enterprise – Site – Area – Line – Cell – Device sauber abbilden muss, reichen die festen vier Ebenen von Sparkplug B nicht aus. Workarounds über Doppelpunkt-Notation in den Group- oder Edge-Node-IDs sind möglich, aber kein sauberer Ersatz für eine native hierarchische Struktur.
- Current-State-Abfrage über den Broker: Da Sparkplug B keine Retained Messages erlaubt, ist der aktuelle Zustand eines Geräts nicht direkt vom Broker abrufbar. Neu hinzukommende Konsumenten müssen auf das nächste DDATA-Event warten oder ein REBIRTH erzwingen – beides ist für viele moderne Architekturen ein No-Go.
- Selektive Subskriptionen auf Teil-Payloads: Die Bündelung mehrerer Metriken in einer Protobuf-Payload verhindert, dass Konsumenten nur Teilinhalte abonnieren. Wer nur eine einzelne Kennzahl benötigt, muss die gesamte Payload entgegennehmen und filtern.
- Hohe Zuverlässigkeitsanforderungen an die Datenübertragung: Da Sparkplug B QoS 0 erzwingt, ist eine garantierte Zustellung („at least once“ oder „exactly once“) nicht möglich. Für Use-Cases, in denen Datenverlust nicht tolerierbar ist (z.B. Track & Trace, produktionssteuernde Anwendungsfälle), ist der Standard ungeeignet.
Fazit
Sparkplug B adressiert wesentliche Herausforderungen bei der Skalierung einer MQTT basierten Infrastruktur in Industrial IoT Umgebungen. Die Definition eines Standards für Topic Namespace, Payloads und Session Management kann erhebliche Vorteile insbesondere in SCADA Umgebungen (Szenario: n:1 Integration) mit sich bringen. Allerdings bringt der Standard auch wesentliche Einschränkungen mit sich, darunter die Abweichung vom weit verbreiteten ISA-95-Modell, die Abhängigkeit von ProtoBuf und Einschränkungen bei den Topic-Elementen. Diese führen zu Problemen, insbesondere im Rahmen einer Unified Namespace (UNS) Architektur (Szenario: n:m Integration).
Daher sollten Unternehmen ihre spezifischen Anforderungen sorgfältig prüfen, unter Berücksichtigung von Faktoren wie der bestehenden Organisationsstruktur, der Expertise ihrer Mitarbeiter und des Anwendungsfalls (n:1 vs. n:m Integration).
