
Open standards play an increasingly important role in Industrial IoT (IIoT). They ensure interoperability between devices and systems from different vendors. Sparkplug B is one such standard, designed to define structured communication in MQTT-based networks. In the following article, we explain how Sparkplug B works, what its strengths and limitations are, and when it is — or isn’t — the right architectural choice.
What is Sparkplug B?
Sparkplug B is an open standard maintained by the Eclipse Foundation. At the time of writing, the current version is Sparkplug 3.0, released in November 2022. Moreover, it is the first official Eclipse Specification published by the Eclipse Sparkplug Working Group. The standard emerged in response to a deliberate design decision in MQTT: the protocol itself does not define how MQTT messages should be structured. While this openness has driven MQTT’s popularity across the IoT ecosystem, the same flexibility creates interoperability problems. As a result, devices and applications from different vendors often cannot communicate seamlessly. To close this gap, Sparkplug B specifies a unified data format and a standardized state management model on top of MQTT, with a particular focus on SCADA environments.
An evolution of Sparkplug A: Sparkplug B builds on the principles of Sparkplug A, an earlier initiative to extend the MQTT standard. However, Sparkplug A ultimately did not gain traction. With Sparkplug B, those concepts were further developed and consolidated into a robust specification that addresses modern industrial requirements. Consequently, it has seen significantly broader adoption in the industry.
Sparkplug B Architecture and Terminology
Sparkplug defines a clear terminology and architecture for organizing messages, ensuring both unambiguous identification and efficient data transmission.

The Sparkplug architecture consists of several key components:
- MQTT Server (Broker): the central element of the Sparkplug architecture, acting as the message hub between Edge Nodes and the Primary Host Application.
- Edge Nodes: located at the edge of the network (e.g., IPCs, gateways, PLCs). They collect data from sensors and actuators and forward it to the broker.
- Edge Devices: physical devices that either capture data (sensors) or perform actions (actuators).
- Primary Host Application: the central application that processes the data — for example, a SCADA system responsible for monitoring, controlling, and optimizing production processes.
Sparkplug B vs. MQTT: The Data Access Model
To illustrate the added value of Sparkplug, the following sections walk through Levels 0 to 5 of the Data Access Model (source: Matthew Parris). This framework describes the essential layers required for interoperability between data producers and consumers. In contrast, undefined layers favor flexibility at the cost of higher integration effort. Therefore, each implementation must be interpreted and integrated individually. Sparkplug B extends the MQTT standard as follows.

Level 2 – Mappings
This layer defines protocol-specific mappings that specify how data is structured and transmitted within the chosen communication protocol. MQTT deliberately leaves this layer open, while Sparkplug provides a standardized mapping for MQTT messages — both for the topic structure and the payload itself. Through defined topic conventions, message types (such as DDATA for device data) can be identified and routed efficiently.
Level 3 – Encoding
Encoding determines how data is prepared for transmission over the network. The chosen data format directly affects transmission efficiency, cross-system compatibility, message size, throughput, and the processing load on the receiver. While MQTT itself prescribes no encoding format, Sparkplug B uses Protobuf — a binary serialization format developed by Google — to encode its messages. As a result, messages are compact and fast to process, even over bandwidth-limited networks. For more details on Protobuf, see our deep dive on data formats.
Level 4 – Values
At Level 4, the focus shifts to which data types are transmitted. A clear specification is essential, because correct interpretation depends on it. Although MQTT does not address this layer, Sparkplug B defines a total of 19 data types. These cover both primitives (such as numbers and strings) and complex structures, as well as user-defined types.
Level 5 – Objects
Finally, Level 5 defines data models and schemas: how data is organized as objects, including their attributes and methods. It is particularly relevant for data interpretation and application logic. However, neither MQTT nor Sparkplug B prescribes a standard at this level. Consequently, data models must be designed individually or based on other specifications. For more on data modeling, see our data modeling guide.
Sparkplug B Topic Namespace
As mentioned, the standard defines the topic namespace at Level 2 of the Data Access Model, establishing the following structure: spBv1.0/group_id/message_type/edge_node_id/[device_id]. This structure enables the identification and grouping of data streams within an IIoT network and consists of the following components:
- spBv1.0 signals that Sparkplug encoding is in use.
- Group ID allows Edge Nodes to be grouped logically (e.g., by geographic location or functional unit).
- Message Type distinguishes between different MQTT message types (e.g., DDATA for device data).
- Edge Node ID and Device ID serve as unique identifiers for edge devices, enabling direct communication and clear mapping of data streams.
A practical example for a manufacturing company with a site in Prague might look like this: spBv1.0/ExampleCompany:Prague/DDATA/MillingArea1:Line1/Cell1
Sparkplug B Message Types
In addition to the topic namespace, Sparkplug defines a set of MQTT message types, published within that namespace, each serving a specific purpose:
- NBIRTH – Birth certificate for Sparkplug Edge Nodes. Announces the initial registration of an Edge Node and transmits its metadata.
- NDEATH – Death certificate for Sparkplug Edge Nodes. Notifies the network of an orderly shutdown or unexpected failure of an Edge Node.
- DBIRTH – Birth certificate for devices. Similar to NBIRTH but for individual devices, reporting their presence and configuration to the network.
- DDEATH – Death certificate for devices. Notifies the network when a device leaves — either through a planned shutdown or due to an error.
- NDATA – Edge Node data message. Transmits operational data from an Edge Node, such as measurements or status information.
- DDATA – Device data message. Transmits operational data from individual devices, such as sensor readings.
- NCMD – Edge Node command message. Enables control commands to be sent to an Edge Node — for triggering actions or changing configurations.
- DCMD – Device command message. Same as NCMD, but specifically for sending commands to individual devices.
- STATE – Sparkplug Host Application state message. Communicates the state of the Sparkplug Host Application, including availability and health, to the network.
Sparkplug B Payload Structure
As noted, Sparkplug payloads use Google Protocol Buffers to provide a compact data transmission format. Each payload contains metrics, metadata, and state information that enable updates on the condition of devices and sensors. Every payload follows a defined structure, standardizing how data is read and written. The example below shows an NDATA message published on the topic spBv1.0/ExampleCompany:Prague/DDATA/MillingArea1:Line1/Cell1. This configuration causes the Host Application to update the values of Supply Voltage, CNCOperationMode, and ActFeedrate.
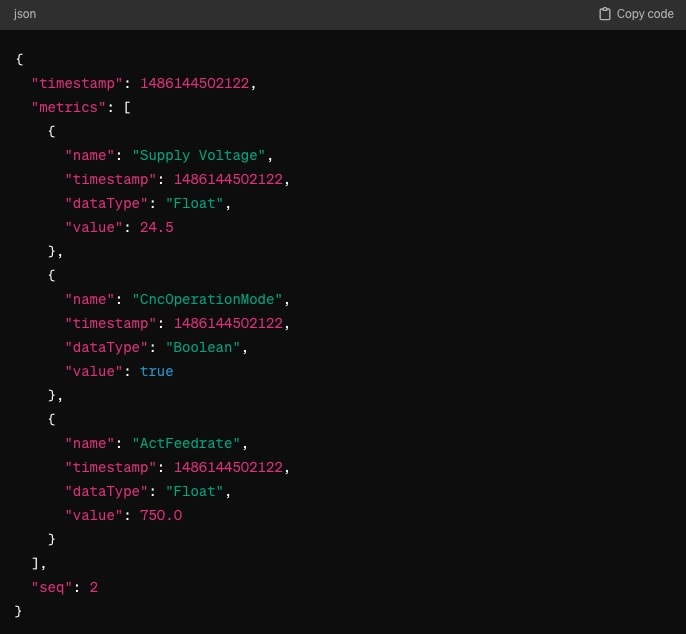
Aliases for Payload Optimization: A key efficiency feature of the Sparkplug payload model is its use of aliases. In the initial NBIRTH or DBIRTH message, each metric is assigned both a unique name (e.g., “MillingArea1.Line1.Cell1.SupplyVoltage”) and a numeric alias (e.g., 1234). In all subsequent NDATA or DDATA messages, only the alias is transmitted instead of the full metric name. Metric names in industrial applications easily reach 30 to 100 characters. As a result, this mechanism can reduce effective payload size by up to 80%. Consequently, Sparkplug B becomes particularly efficient in bandwidth-limited networks such as cellular, satellite, or LPWAN. Alias-to-name resolution happens exclusively on the consumer side, based on the previously received birth message. If that message is missing, the payload becomes uninterpretable — one of the reasons Sparkplug B enforces strict birth/death sequencing.
State Management: Sparkplug B vs. Plain MQTT
One of Sparkplug B’s most significant advantages over plain MQTT is its standardized state management. While MQTT deliberately makes no assertions about the state of connected clients, Sparkplug B defines a clear lifecycle for Edge Nodes and devices — the foundation for deterministic SCADA applications.
The Sparkplug B Lifecycle
Sparkplug defines the sequence of state and data messages an Edge Node exchanges over the duration of a connection. Therefore, five building blocks form the foundation:

- Birth Messages (NBIRTH/DBIRTH): When an Edge Node or device connects to the broker, it sends a birth message containing all available metrics (incl. data types, aliases, and initial values). Consumers can immediately determine all available data and the system state.
- Death Messages (NDEATH/DDEATH): A death message is triggered either by an orderly disconnect or by an unexpected connection loss.
- Last Will and Testament (LWT): The trigger for an NDEATH is not the Edge Node itself but MQTT’s native “Last Will and Testament” mechanism. During CONNECT, the Edge Node registers a predefined NDEATH as its LWT with the broker. If the connection drops unexpectedly (keep-alive timeout, network failure, power loss), the broker publishes the NDEATH. As a result, all consumers learn about the failure without active polling. Hereby, Sparkplug B standardizes the LWT message’s format and meaning.
- Primary Application as Source of Truth: The Primary Host Application monitors all birth and death messages. Moreover, it continuously validates the availability of every node and device. If a node fails, the host can trigger alarms, failover mechanisms, or a full re-synchronization.
- Sequence Numbers (seq, bdSeq): Two sequence numbers safeguard deterministic recovery. The seq counter (0–255, reset to 0 at every NBIRTH) increments across all operational messages. If the sequence breaks, the Primary Host issues an NCMD/REBIRTH command to trigger a full re-sync. By contrast, the bdSeq (64-bit, incremented per session) prevents a delayed NDEATH from a previous session from being misapplied to the current one. Together, both compensate for the missing delivery guarantee under QoS 0. As a result, individual values may be lost, but the overall state of the Edge Node remains consistent.
State Management in Plain MQTT
Plain MQTT offers no comparable functionality. Any state tracking must be modeled manually:
- LWT Messages: MQTT supports LWT as a base mechanism, but without a standardized payload format. Both content and interpretation must be defined per project.
- Heartbeats / Keep-alive: Clients can send periodic heartbeats, which other participants must actively monitor. Without LWT, an unexpected failure goes undetected until the next heartbeat interval expires.
- Custom Birth/Death via Retained Messages: Custom implementations (e.g., a retained topic such as “client/xyz/status”) are possible and common in Unified Namespace (UNS) architectures. However, they are not natively interoperable across systems from different vendors.
Comparison: State Management in Sparkplug B vs. Plain MQTT
Standardized state management is one of Sparkplug B’s most valuable contributions over plain MQTT. For this reason, it has become so popular in classical SCADA scenarios.
| Feature | Sparkplug B | Plain MQTT |
|---|---|---|
| Standardized birth/death messages | ✅ Yes | ❌ No (must be implemented manually) |
| Automatic status updates via LWT | ✅ Yes (NDEATH/DDEATH) | ✅ Yes, but unstandardized |
| Centralized state management | ✅ Yes (Primary Application) | ❌ No |
| Out-of-the-box availability detection | ✅ Yes | ❌ No, project-specific |
| Hierarchical lifecycle (Node + Device) | ✅ Yes | ❌ No |
| Sequence numbers against data loss | ✅ Yes | ❌ No |
| Current state retrievable from broker | ❌ No (no retained messages) | ✅ Yes (via retained messages) |
The tight coupling to the Primary Application and the absence of retained messages, however, become limitations in a UNS context — as the following section explains.
Sparkplug B Pros and Cons
Sparkplug B brings both significant benefits and meaningful trade-offs in industrial environments. Both sides need to be weighed carefully.
Pros
- Payload definition and interoperability: By using consistently interpreted data types across the MQTT ecosystem, Sparkplug B significantly improves interoperability.
- Session management: The standard provides a unified approach to managing session state across all connected components, simplifying coordination and synchronization.
- Defined topic naming: By structuring the MQTT topic namespace, Sparkplug promotes clarity and consistency in communication.
Cons
- Complexity: The dependency on Protobuf is familiar to most IT professionals, but it can introduce additional complexity for OT staff less accustomed to this encoding.
- Bandwidth savings vs. complexity: For manufacturing systems connected via wired Ethernet, the bandwidth savings Sparkplug B offers may not justify its additional complexity.
- Primary Application: The concept of a “Primary Application” can introduce challenges. If the Primary Application goes down, machines stop transmitting data. This is particularly problematic in a Unified Namespace (UNS) architecture.
- Topic element limitations: Sparkplug restricts the number of topic elements. As a result, scalability and compatibility with complex organizational hierarchies such as ISA-95 are limited. In addition, restrictions affect wildcard usage (e.g., no subscription to all messages from a production line) and selective subscriptions to subsets of a data payload.
- QoS 0 for all data and lifecycle messages: Sparkplug B mandates QoS 0 for the operational message types NBIRTH, DBIRTH, NDATA, DDATA, NDEATH, and DDEATH. At this QoS level, the broker transmits messages on an “at most once” basis. Consequently, messages can be lost (more on QoS here). However, STATE messages from the Primary Host Application are transmitted with QoS 1, since host availability must be reliably signaled.
- No retained messages: Sparkplug B does not allow the use of the retain flag for data or birth messages. As a result, the “current state” cannot be stored on the broker, which makes Sparkplug B unsuitable for many use cases (more on retained messages here).
When to Use Sparkplug B (and When Not To)
Whether Sparkplug B is the right choice depends less on the standard itself than on the target architecture. Specifically, the decisive question is whether its strengths outweigh its structural limitations. These strengths include defined state management, compact payloads, and plug-and-play behavior in n:1 architectures.
When Sparkplug B Is the Right Choice
There are clearly defined scenarios in which Sparkplug B is not just useful, but the preferred option:
- Classical SCADA modernization (n:1 integration): Suppose an existing SCADA system (e.g., Ignition, AVEVA, zenon) acts as the central host application, and Edge Nodes or PLCs need structured integration. In this case, Sparkplug B plays to its strengths. Defined birth/death certificates, sequence numbers, and a consistent topic namespace significantly reduce integration effort. Indeed, this is the scenario in which the standard originated. Moreover, the data architecture is typically dictated by a single vendor (single-vendor stack). As a result, the ISA-95 conflict largely disappears, and the rigid topic hierarchy becomes a guardrail rather than a limitation.
- Bandwidth-limited and unreliable networks: In scenarios involving cellular, satellite, or LPWAN connectivity, Protobuf encoding and aliases offer measurable benefits. This is typical for oil & gas, water/wastewater, wind farms, or other distributed assets. Furthermore, the bandwidth savings justify the added complexity, since data volume directly translates into operational cost and latency.
When Sparkplug B Is Not the Right Choice
Equally well-defined are scenarios in which the standard’s limitations outweigh its benefits — and a Unified Namespace (UNS) architecture is the better fit:
- Multiple, functionally independent consumers (n:m integration): Suppose MES, historian, analytics platform, AI applications, and ERP need to access the same data streams in parallel. In that case, the rigid Primary Host concept becomes a bottleneck. Moreover, each consumer has its own requirements regarding granularity, frequency, and data model — a use case Sparkplug B was never designed for.
- ISA-95-conformant structuring: If the topic hierarchy must cleanly represent the layers Enterprise – Site – Area – Line – Cell – Device, the fixed four levels of Sparkplug B are not sufficient. Workarounds using colon notation in the Group or Edge Node IDs are possible. However, they are no clean substitute for a native hierarchical structure.
- Querying current state from the broker: Since Sparkplug B does not allow retained messages, the current state of a device cannot be queried directly. Instead, new consumers must wait for the next DDATA event or trigger a REBIRTH. For many modern architectures, both options are non-starters.
- Selective subscriptions to partial payloads: Bundling multiple metrics into a single Protobuf payload prevents consumers from subscribing to only parts of it. Therefore, a consumer interested in a single KPI must accept the full payload and filter it client-side.
- High reliability requirements for data transmission: Since Sparkplug B enforces QoS 0, guaranteed delivery (“at least once” or “exactly once”) is not possible. As a result, the standard is unsuitable for use cases where data loss is unacceptable (e.g., track & trace, production-control applications).
Conclusion
Sparkplug B addresses essential challenges in scaling MQTT-based infrastructures within Industrial IoT environments. By defining a standard for topic namespace, payloads, and session management, it offers significant benefits — particularly in SCADA environments (n:1 integration). However, the standard also introduces meaningful limitations. For example, it deviates from the widely adopted ISA-95 model, depends on Protobuf, and constrains topic elements. As a result, these trade-offs become problematic in the context of a Unified Namespace (UNS) architecture (n:m integration).
Therefore, companies should carefully assess their specific requirements. Key factors include existing organizational structure, in-house expertise, and the use case at hand (n:1 vs. n:m integration).
