
Im Industrial IoT hält es ein hartnäckiges Missverständnis: Nur mit einer großen Vielfalt an Datentypen lassen sich komplexe Produktionsprozesse sinnvoll abbilden. Die Praxis zeigt jedoch das Gegenteil. Für den Aufbau eines skalierbaren Unified Namespace (UNS) genügen oft wenige, gezielt ausgewählte Datentypen. Diese Reduktion sorgt an der Schnittstelle zwischen IT und OT für mehr Effizienz und Konsistenz. Dieser Artikel zeigt, warum „weniger mehr ist“, welche Vorteile eine schlanke Datentypen-Strategie im UNS bringt und wo ihre Grenzen liegen. Eine Einführung zum Thema IT/OT Interoperabilität im UNS finden Sie hier.
Vielfalt an Datentypen: Vor- und Nachteile
Die gängige Annahme lautet: Je mehr Datentypen vorhanden sind, desto präziser lassen sich industrielle Daten abbilden. Und tatsächlich bringt ein breites Set an Datentypen einige Vorteile, insbesondere auf OT-Ebene (Level 2 und tiefer):
- Robustheit und Typ-Sicherheit: Fehler werden früh erkannt, oft schon zur Compile-Zeit statt erst im laufenden Betrieb.
- Echtzeit-Fähigkeit: Spezifische Datentypen können bei zeitkritischen Prozessen die Performance steigern.
- Speicher-Effizienz: Gerade in ressourcenlimitierten Steuerungen hilft die Wahl des optimalen Datentyps, Speicherplatz zu sparen.
Doch beim Übergang von der OT in die IT/OT-Integrationsebene (Level 3 und höher) kehrt sich das Bild um. Hier wirkt eine Vielzahl an Datentypen weniger hilfreich, sondern eher hinderlich. Denn ein Industrial UNS lebt von Standardisierung und einfacher Integration. Werden zu viele Typen zugelassen, entstehen schnell Nachteile:
-
- Höhere Systemkomplexität: Mehr Datentypen bedeuten mehr Regeln, mehr Ausnahmen und mehr Aufwand im Handling.
- Steigende Fehleranfälligkeit: Unterschiedliche Interpretationen von Datentypen erhöhen die Gefahr von Missverständnissen zwischen Systemen.
- Integrationsprobleme: Ein heterogenes Typenset erschwert die reibungslose Anbindung neuer Systeme und Applikationen.
Gerade in datengetriebenen IIoT-Architekturen wirkt sich diese Komplexität negativ auf Skalierbarkeit und Wartbarkeit aus.
OT vs. IT/OT – Unterschiedliche Anforderungen
Die Anforderungen an Datentypen unterscheiden sich je nach Ebene im Industrial IoT deutlich. Während in der Operational Technology (OT, Level 2 und tiefer) Effizienz und Echtzeitfähigkeit dominieren, zählt auf der IT/OT-Integrations- und UNS-Ebene (Level 3 und höher) vor allem Standardisierung und Interoperabilität.
Operational Technology (Level 2 und tiefer): Auf der Steuerungs- und Maschinenebene stehen Echtzeitfähigkeit, Präzision und Speicher-Effizienz im Vordergrund. Hier macht ein breites Spektrum an Datentypen Sinn – z. B. float16, int8 oder spezielle numerische Typen für hochpräzise Messungen. Das Ergebnis: maximale Effizienz im lokalen Kontext, angepasst an die individuellen Anforderungen der Maschine oder Steuerung.
IT/OT-Integration (UNS-Ebene, Leven 3 und höher): Auf der Integrationsebene gelten andere Prioritäten. Hier steht Standardisierung, Skalierbarkeit und Interoperabilität über den gesamten Industrial IoT Stack im Vordergrund. Statt Vielfalt ist eine Reduktion auf wenige universelle Datentypen im Unified Namespace (UNS) wie Integer, String, Boolean und Timestamp entscheidend. Ziel ist die reibungslose Weiterverarbeitung, Speicherung und Analyse in MES, ERP, Data Lakes oder Cloud-Systemen.
Die passende Strategie: Weniger ist mehr im UNS
Abgeleitet aus den Anforderungen von OT und IT/OT, folgend eine Übersicht über die unterschiedlichen Datentyp-Strategien. Die Faustregel lautet: OT = Datentypen-Vielfalt für lokale Effizienz, UNS = Minimaltypen für globale Skalierbarkeit.
| Anforderung | OT (Level 2 und tiefer) | IT/OT-Integration (UNS-Ebene) | Datentyp-Strategie |
|---|---|---|---|
| Echtzeitfähigkeit | Harte Latenzbudgets; optimierte Rechenpfade. | Keine harten Echtzeit-Anforderungen im Backbone. | OT: Datentypen-Vielfalt (z.B. int8, float16) UNS: Minimale Datentypen (z.B. Integer, String) |
| Robustheit & Typ-Sicherheit | Strikte, eng typisierte Modelle zur Fehlervermeidung zur Compile-/Deploy-Zeit. | Konsistenz durch Standard-Schemata wichtiger als enge Maschinentypisierung. | OT: Datentypen-Vielfalt UNS: Minimale Datentypen + Schema Registry |
| Speicher-/Ressourceneffizienz | Kleinstmögliche Breiten zur Schonung von CPU/RAM (z.B. uint16). | Ressourcen sind weniger kritisch als Lesbarkeit & Vereinheitlichung. | OT: Datentypen-Vielfalt UNS: Minimale Datentypen |
| Standardisierung | Geräte-/Hersteller-spezifisch; hohe Varianz akzeptiert. | Strikte Vereinheitlichung über Domänen hinweg (UNS als „gemeinsame Sprache“). | OT: Nutzung von Typen Standards (z.B. OPC UA) UNS: Minimale Datentypen zur Reduktion von Mapping-Aufwand |
| Interoperabilität | Lokal optimiert, oft proprietär. | Hoch; systemübergreifender Austausch (MES, ERP, Data Lake, Cloud). | OT: Nutzung von Typen Standards (z.B. OPC UA) UNS: Minimale Datentypen |
| Integrationsaufwand | Gering innerhalb der Zelle, hoch beim Übergang zu IT. | Niedrig durch Konsolidierung auf wenige, klare Typen. | OT: Datentypen-Vielfalt (lokaler Fit) UNS: Minimale Datentypen (globaler Fit) |
| Fehleranfälligkeit | Niedrig durch enge Typisierung im lokalen Kontext. | Niedrig durch weniger Interpretationen & eindeutige Felder. | OT: Datentypen-Vielfalt UNS: Minimale Datentypen + Validierungsregeln |
| Skalierbarkeit & Wartbarkeit | Skalierung begrenzt durch heterogene Typwelten. | Hohe Skalierbarkeit dank vereinheitlichter Datentypen im UNS. | OT: Nutzung von Typen Standards (z.B. OPC UA) UNS: Minimale Datentypen (einfachere Pipelines & Governance) |
Grenzen des Minimaltypen-Ansatzes
So sinnvoll die Strategie minimaler Datentypen im Unified Namespace auch ist – es gibt Szenarien im Industrial IoT, in denen eine erweiterte Typenvielfalt unverzichtbar bleibt. Typische Ausnahmen sind hochpräzise Energiemessungen, welche oft float64 benötigen, da kleinere Typen nicht ausreichen sowie Bild- und Sensordaten. Wichtig ist, diese Fälle als gezielte Ausnahmen zu behandeln – nicht als Standard. Der UNS sollte schlank bleiben und nur dort zusätzliche Typen zulassen, wo die fachliche Notwendigkeit gegeben ist.
Datenformate und ihre Auswirkungen auf Datentypen
Neben den Datentypen selbst spielt auch das gewählte Austauschformat eine zentrale Rolle. Unterschiedliche Serialisierungsformate gehen unterschiedlich mit Typisierung, Lesbarkeit und Effizienz um:
- XML: Stark typisiert, aber sehr verbos. Gut für komplexe Strukturen, jedoch mit hohem Overhead und eher hinderlich für minimale Datentypen im UNS.
- JSON: Flexibel, leichtgewichtig und menschenlesbar. In der Praxis oft Standard für UNS-Implementierungen, da es wenige primitive Typen (Number, String, Boolean, Null) bereitstellt und damit den Ansatz minimaler Datentypen unterstützt.
- Protobuf (Protocol Buffers): Binär, hoch effizient und streng typisiert. Ideal für Performance und geringe Bandbreiten, erfordert aber ein vordefiniertes Schema. Hier wird die Typenreduktion durch klare Felddefinitionen und numerische IDs abgesichert.
Die Wahl des Formats beeinflusst also, wie „eng“ oder „locker“ Datentypen im UNS gehandhabt werden. JSON etwa fördert Vereinfachung durch reduzierte Typen, während Protobuf Typensicherheit erzwingt. Entscheidend ist: Unabhängig vom Format führt die Reduktion auf wenige Basistypen zu höherer Interoperabilität. Weitere Details zu Datenformaten und ihren Anwendungsgebieten finden Sie hier.
Praxisbeispiel
In der Praxis zeigt sich, dass die meisten Anwendungsfälle bereits mit Datentypen wie Objects, Arrays, Integer, Boolean, String und Timestamp abgedeckt werden können. Um das zu veranschaulichen, betrachten wir einen realen Datenfluss – von der Maschine bis in ein exemplarisches Dashboard:
1. OT-Sensor (Level 1–2)
- Ein Vibrationssensor liefert Rohdaten als int64 für Schwingungsstärke.
- Zusätzlich sendet er einen Statusbit als String (normal, Alarm).
2. i-flow Edge: liest die OT-Daten und wandelt sie für den UNS auf ein vereinfachtes Schema
- int64 → Integer
- String wird Boolean (true=normal, false=Alarm)
- Ergänzung eines Timestamp (UTC, ISO 8601) für zeitliche Korrelation.
3. Unified Namespace (UNS, z. B. MQTT/JSON): Daten werden standardisiert publiziert
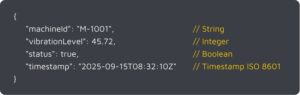
4. Dashboard: vereinheitlichten Datentypen ermöglichen sofortige Weiterverarbeitung
- Integer → Zeitreihenanalyse (Trend, Schwellwertüberschreitung).
- Boolean → Klassifizierung (OK/Alarm).
- Timestamp → Korrelation mit anderen Events.
5. Validierung & Governance: Damit die Strategie dauerhaft funktioniert, braucht es klare Regeln und zentrale Kontrolle (Governance). In der Praxis geschieht das über Schema- und Topic-Governance in einem zentralen Management Tool für eine Schema-Registry sowie Schema-Validierung.
Fazit: So viel wie nötig, so wenig wie möglich
Für einen skalierbaren Unified Namespace (UNS) braucht es keine große Vielfalt an Datentypen. Der Ansatz minimaler Datentypen reduziert Komplexität, steigert Interoperabilität und sorgt für konsistente Datenqualität im Industrial IoT. Während die OT-Ebene feingranulare Typen für Echtzeit und Effizienz nutzt, gewinnt die IT/OT-Integration durch Typen-Reduktion an Klarheit und Konsistenz.
