
Apache Kafka ist eine leistungsstarke Event-Streaming-Plattform, die in hoch skalierbaren Architekturen zum Einsatz kommt. Die Architektur von Kafka wurde mit Blick auf Durchsatz, Skalierbarkeit und Haltbarkeit von Datenströmen konzipiert. Gerade aufgrund dieser Eigenschaften stellt sich in vielen Projekten die Frage, ob Kafka oder MQTT die bessere Wahl im Industrial IoT ist. Dieser Artikel beantwortet diese Frage und vergleicht die Technologien hinsichtlich ihrer Einsatzgebiete, Stärken und Grenzen.
Wer darüber hinaus auch AMQP und NATS in die Bewertung einbeziehen möchte, findet in unserem Message Broker Vergleich im IIoT eine umfassende Gegenüberstellung aller vier Protokolle.
Die Entstehung von Kafka: Von LinkedIn zu Open Source
Kafka wurde ursprünglich von LinkedIn entwickelt und später als Open-Source-Projekt an die Apache Software Foundation übergeben. Dabei diente Kafka dazu, die Herausforderungen von LinkedIn in Bezug auf die Verarbeitung und Bereitstellung großer Datenmengen in Echtzeit zu bewältigen. Der Name „Kafka“ wurde nach dem berühmten tschechischen Schriftsteller Franz Kafka gewählt. Dies spiegelt die Zielsetzung der robusten und fehlerfreien Datenübertragung in einer komplexen und oft chaotisch verteilten Umgebung wider.
Event-basierte Kommunikation
Kafka minimiert die Bandbreitennutzung, indem es von einer konventionellen „Poll-Response“ Verhalten (wie z.B. bei der OPC UA Client-Server Architektur) zu einem event-basierten „Publish-Subscribe“ Verhalten übergeht. Event-basiert bedeutet, ein Datenkonsument wartet auf Datenänderungen (anstelle diese zyklisch abzufragen). Dies ermöglicht eine ereignisgesteuerte Echtzeit-Kommunikation zwischen Geräten und Anwendungen innerhalb des Unternehmens und darüber hinaus. Weitere Informationen sind hier zu finden.

Vorteile und Nachteile von Kafka
Apache Kafka hat im industriellen Umfeld und unternehmensweitem Kontext insbesondere folgende Vorteile:
- Verarbeitung großer Datenmengen: Kafka kann riesige Mengen an Daten effektiv bewältigen und bietet hohe Durchsatzraten. Dies ist insbesondere bei der Verarbeitung großer Datenströme in industriellen Umgebungen hilfreich.
- Persistenz und Fehlertoleranz: Kafka speichert Daten dauerhaft und repliziert sie über mehrere Broker hinweg. Das bedeutet, Nachrichtenverlust ist weitestgehend ausgeschlossen, selbst bei Serverausfällen. Zudem können Daten können von Consumer-Systemen jederzeit nachträglich gelesen werden (Replay-Funktionalität).
- Hohe Skalierbarkeit und Performance: Kafka ist für hochparallele Datenströme ausgelegt und verarbeitet problemlos Millionen von Nachrichten pro Sekunde. Dank horizontaler Skalierung (mehr Broker = mehr Leistung) bleibt die Latenz auch bei wachsender Datenmenge gering, während der Durchsatz konstant hoch ist. Damit eignet sich Kafka ideal für die Verarbeitung großer Datenmengen in Echtzeit – etwa in Streaming- oder IoT-Anwendungen.
Trotz seiner Stärken bringt Apache Kafka auch einige Herausforderungen mit sich, insbesondere im industriellen Einsatz:
- Hoher Infrastruktur- und Betriebsaufwand: Kafka ist ein komplexes System, das den Betrieb mehrerer Komponenten (Broker, ZooKeeper/KRaft, Schema Registry, etc.) erfordert. Die Einrichtung, Überwachung und Wartung erfordern spezialisiertes Know-how und verursachen einen nicht unerheblichen administrativen Aufwand.
- Hoher Ressourcenverbrauch: Kafka ist für hohe Datenraten und dauerhafte Speicherung ausgelegt, was mit einem hohen Bedarf an CPU, RAM und Festplattenspeicher einhergeht. Besonders bei großen Datenmengen, vielen Partitionen oder langer Aufbewahrungsdauer kann dies schnell zu einer ressourcenintensiven Systemlandschaft führen.
- Eingeschränkte Eignung für kleine oder sporadische Datenmengen: Kafka ist auf hohe Durchsatzraten und kontinuierliche Datenströme optimiert. In Szenarien mit kleinen Nachrichten oder unregelmäßigen Datenintervallen ist Kafka meist überdimensioniert und ineffizient. Beispiel: Ein Temperaturwert alle 5 Sekunden erzeugt pro Nachricht einen unverhältnismäßig großen Overhead gegenüber anderen Protokollen wie MQTT.
Kafka im Industrial IoT
Produzierende Unternehmen setzen Kafka insbesondere in Umgebungen mit großen Skalierungsanforderungen ein, um Datenströme zwischen Systemen und Anwendungen zu übertragen. Die Plattform stellt dabei sicher, dass diese Daten an alle Abonnenten in einer zuverlässigen und fehlertoleranten Weise weitergeleitet werden. Kafka gewinnt daher in folgenden Anwendungsfällen an Bedeutung:
- Kommunikation über verschiedene Schichten: Kafka findet zunehmend in großen produzierenden Unternehmen (z.B. Automotive OEMs) als Kommunikationsprotokoll für die Enterprise- und Connected-World Schicht des ISA95-Modells Einsatz. Ziel dabei ist es, Integrationskosten zu minimieren und die Skalierbarkeit der Systemarchitektur zu erhöhen. Dies ist insbesondere im Rahmen von Architekturen wie dem Unified Namespace (UNS) von Bedeutung.
- Unified Namespace (UNS): Die UNS-Architektur bietet eine zentrale, nicht-hierarchische Systemarchitektur, in der alle Fabrikdaten über eine einheitliche Namenskonvention und Datenstruktur in einem zentralen Message Broker zugänglich sind. Kafka unterstützt diesen Ansatz, indem es Datenproduzenten ermöglicht, Daten im zentralen Message Broker kontinuierlich zu publizieren. Dies folgt dem Prinzip „publish once, distribute everywhere“, wodurch Daten einmal veröffentlicht und dann von beliebig vielen Systemen und Anwendungen abonniert werden können. Weitere Informationen zum UNS finden Sie in unserem Blog.
")
MQTT oder Kafka: Was passt besser?
Sowohl MQTT als auch Kafka sind in der Welt der Datenübertragung und -verarbeitung weit verbreitet und haben sich in diversen Anwendungsfällen als Broker-basierte Publish / Subscribe Architektur bewährt. Beide Technologien ermöglichen es, Daten zwischen verschiedenen Systemen oder Komponenten zu übertragen. Allerdings bieten die Technologien unterschiedliche Schwerpunkte und Funktionen.
Wo liegen die Unterschiede?
MQTT und Kafka unterscheiden sich deutlich in der Leistungsfähigkeit und den typischen Einsatzbereichen.
- Durchsatz und Latenz:
- MQTT: Bietet eine niedrigere Latenz und ist ideal für Anwendungsfälle, in denen schnelle Lieferung von Nachrichten kritisch ist.
- Kafka: Zwar ist Kafka für hohe Durchsatzraten optimiert. Dies geschieht allerdings häufig durch Batching, was die Nachrichtenlatenz im Vergleich zu MQTT erhöht.
- Datenspeicherung:
- MQTT: Ist in erster Linie darauf ausgerichtet, Nachrichten mit geringer Latenz zu übertragen und bietet keine Funktionen zur Langzeitspeicherung von Daten.
- Kafka: Bietet robuste Funktionen zur Datenspeicherung und kann Nachrichten für längere Zeit (konfigurierbar) aufbewahren, um sie erneut zu verarbeiten.
- Zustellungsgarantien für Nachrichten:
- MQTT: Nutzer konfigurieren pro Anwendungsfall die Zustellungsgarantie über Quality of Service (QoS) Stufen – “at most once” (QoS 0, Fire-and-Forget), “at least once” (QoS 1, evtl. Duplikate) oder “exactly once” (QoS 2, keine Duplikate oder Verluste).
- Kafka: Verwendet in der Standardeinstellung eine at-least-once Semantik, d.h. Nachrichten werden mindestens einmal ausgeliefert (Duplikate sind möglich). Nur durch Mehraufwand kann der Nutzer über Producer- und Consumer-Einstellungen (z.B. acks=all und Transaktionen) eine exactly-once Semantik erreichen.
- Fehlertoleranz und Wiederherstellung:
- MQTT: Hat Mechanismen für die Bestätigung von Nachrichten, aber keine native Unterstützung für „Replays“ zur späteren Wiederherstellung.
- Kafka: Starke Fähigkeiten zur Wiederherstellung von Daten nach einem Ausfall dank persistenter Speicherarchitektur und „Replay“ Funktionalität.
- Implementierungs- und Wartungsaufwand
- MQTT: Die Implementierung, Konfiguration, sowie das Management und Monitoring von MQTT-Brokern sind vergleichsweise einfach.
- Kafka: Kafka ist deutlich komplizierter und aufwendiger. Dabei erfordern Themen wie Cluster-Management, Partitionierung, Replikation und Monitoring tiefgehendes Know-how und eine dedizierte Infrastruktur.
- Ressourcenbedarf:
- MQTT: Ist ressourcenschonend konzipiert und eignet sich ideal für den Einsatz auf Hardware mit begrenzter Rechenleistung, Speicher und Bandbreite – insbesondere im Edge-Bereich.
- Kafka: Bietet eine hohe Performance und Skalierbarkeit, erfordert dafür jedoch deutlich mehr Systemressourcen. Dies macht Kafka für den direkten Einsatz auf ressourcenbeschränkter Edge-Hardware ungeeignet.
Zusammenfassung der Unterschiede
| Aspekt | MQTT | Kafka |
|---|---|---|
| Durchsatz und Latenz | Niedrige Latenz, ideal für zeitkritische Nachrichtenübertragung. | Hoher Durchsatz durch Batching, aber höhere Latenz als MQTT. |
| Datenspeicherung | Keine native Langzeitspeicherung, Fokus auf Echtzeit-Übertragung. | Persistente Speicherung mit konfigurierbarer Aufbewahrung und Replay. |
| Zustellungsgarantien | QoS-Stufen konfigurierbar: 0 (at most once), 1 (at least once), 2 (exactly once). | Standardmäßig at least once; exactly once nur mit zusätzlichem Aufwand. |
| Fehlertoleranz & Wiederherstellung | Bestätigung möglich, aber keine native Unterstützung für Replay oder Langzeitspeicherung. | Hohe Fehlertoleranz durch persistente Speicherung und Replay-Funktion. |
| Implementierung & Wartung | Einfache Einrichtung, Konfiguration und Wartung. | Komplexes Setup mit höherem Wartungsaufwand (z. B. Cluster-Management). |
| Ressourcenbedarf | Ressourcenschonend, ideal für Edge-Geräte mit begrenzter Leistung. | Hoher Ressourcenbedarf, für Edge-Geräte ungeeignet. |
Was sind die Gemeinsamkeiten von MQTT und Kafka?
Trotz ihrer unterschiedlichen Schwerpunkte und Einsatzbereiche weisen MQTT und Apache Kafka eine Reihe grundlegender Gemeinsamkeiten auf:
- Datentransfer auf Basis Publish/Subscribe: Beide Technologien basieren auf dem Publish/Subscribe-Modell. Das bedeutet, dass Datenproduzenten (Publisher) Nachrichten an ein zentrales System senden, während Konsumenten (Subscriber) gezielt Nachrichten empfangen, ohne direkt mit dem Sender verbunden zu sein. Diese entkoppelte Kommunikation ermöglicht eine flexible und skalierbare Architektur.
- Offene Standards & breite Unterstützung: MQTT und Kafka sind Open-Source – beide werden von einer großen Community sowie von zahlreichen industriellen und cloudbasierten Plattformen unterstützt. Dies ermöglicht eine breite Integration in bestehende Systeme.
- Skalierbarkeit und Redundanz: Beide Technologien sind für den hochverfügbaren Betrieb ausgelegt. Sowohl MQTT-Broker als auch Kafka-Cluster lassen sich horizontal skalieren und redundant betreiben, um Ausfallsicherheit und kontinuierliche Datenverfügbarkeit sicherzustellen.
- Verteilte Systeme: Beide Technologien unterstützen verteilte Systeme und können in Umgebungen mit mehreren Servern und Clients implementiert werden.
- Zuverlässige Datenübertragung: Sowohl Kafka als auch MQTT bieten Mechanismen zur Gewährleistung der Datenübertragung, wenngleich die Implementierung und die Garantien unterschiedlich sind.
MQTT vs. Kafka: Typische Einsatzgebiete im Industrial IoT
Im Industrial IoT unterscheiden sich MQTT und Apache Kafka nicht nur in ihrer technologischen Basis, sondern vor allem in ihrem typischen Einsatzbereich innerhalb von IT/OT-Architekturen.
IT/OT Anforderungen im Industrial IoT
Je nach Einsatzebene – OT, IT oder IT/OT-übergreifend – ergeben sich unterschiedliche Anforderungen an eine IIoT-Datenarchitektur. Die folgende Übersicht zeigt, welche Anforderungen MQTT und Kafka jeweils besonders gut erfüllen:
| Relevanz | Anforderung | MQTT | Kafka |
|---|---|---|---|
| OT | Edge-fähigkeit (ressourcenschonender Betrieb) | ✅ | |
| OT | Leichtgewichtiges Protokoll | ✅ | |
| OT | Latenzoptimierte Datenübertragung | ✅ | |
| OT | Skalierbar für viele Clients mit kleiner Payload | ✅ | |
| OT | Einfache Implementierung & Wartung | ✅ | |
| IT/OT | Eventbasierte Kommunikation (Publish/Subscribe) | ✅ | ✅ |
| IT/OT | Zuverlässige Datenübertragung | ✅ | ✅ |
| IT/OT | OT/IT-Sicherheit (TLS, Authentifizierung, ACLs) | ✅ | ✅ |
| IT/OT | Redundanz (hochverfügbarer Betrieb) | ✅ | ✅ |
| IT/OT | Open-Source-Technologie mit breiter Unterstützung | ✅ | ✅ |
| IT | Skalierbare Verarbeitung großer Datenmengen | ✅ | |
| IT | Persistente Speicherung & Replay-Fähigkeit | ✅ |
Der passende Broker für Ihren Use-Case
Im industriellen Umfeld gibt es zahlreiche Anwendungsfälle, in denen MQTT oder Kafka klare technische Vorteile bie. Insbesondere OT-nahe Kommunikation, mobile Anwendungen und energieeffiziente Sensorik profitieren stark vom MQTT-Protokolldesign.
1. Leichtgewichtige, latenzarme OT-Kommunikation
Beispiele: SPS sendet Zykluszeiten im Bereich 1–10 ms, Beckhoff-/Siemens-PLC veröffentlicht Taktzeitdaten direkt aus der Steuerung.
Warum MQTT? Minimaler Overhead, QoS für zuverlässige Zustellung, Geeignet für eingebettete Geräte mit geringem Footprint
Warum nicht Kafka? Kafka erfordert einen vollwertigen Producer-Client auf der Edge – ressourcenintensiv, ohne QoS-Semantik.
2. Bidirektionale Kommunikation / Command & Control
Beispiel: Remote-Parameteränderung (z. B. SetSpeed) an einer Maschine.
Warum MQTT? Retained Messages → Maschine erhält Parameter sofort nach Neustart, Last Will signalisiert Ausfälle, Leichtgewichtiges Publish/Subscribe-Modell
Warum nicht Kafka? Consumer lesen nur vorwärts (kein „aktueller Zustand“), Keine State- oder Retain-Semantik, Keine QoS oder Zustandsverwaltung
Hinweis: Für echtes Command & Control sind Punkt-zu-Punkt-Integrationen mit Request/Response (z. B. über i-flow Edge) oft besser geeignet, da sie verlässliche End-to-End-Rückmeldungen ermöglichen – etwas, das Broker-basierte Kommunikation nicht garantieren kann.
3. Energieeffiziente oder mobil vernetzte Geräte
Beispiele: Batteriebetriebene Sensoren (Temperatur, Vibration), AGVs melden Position & erhalten Jobupdates, Tablets/Wearables mit Funklöchern in der Fabrik
Warum MQTT? Entwickelt für Low-Power- und instabile Netzwerke, Session Resume für nahtlose Wiederverbindung, QoS-Level sichern zuverlässige Zustellung, Retained Messages liefern sofort den letzten Zustand, Last Will erkennt Geräteausfälle
Warum nicht Kafka? Zu schwergewichtig für Embedded-/Battery-Devices, benötigt dauerhafte TCP-Verbindungen, keine QoS-, Session- oder Store-and-Forward-Mechanismen
4. Hochskalierbare, verteilte Event-Streams für Big Data & Analytics
Beispiel: KPI-Berechnung auf Event-Streams wie z.B. komplexe OEE-Analysen über 120 Fabriken.
Warum Kafka? Partitionierung, Sehr hohe Datenvolumina (GB–TB pro Tag), Replays für ML/Analytics, Nahtlose Integration in Stream Processing (Flink, Kafka Streams)
Warum nicht MQTT? MQTT ist ein reines Transportprotokoll – keine Replays, keine Stream-Partitionen.
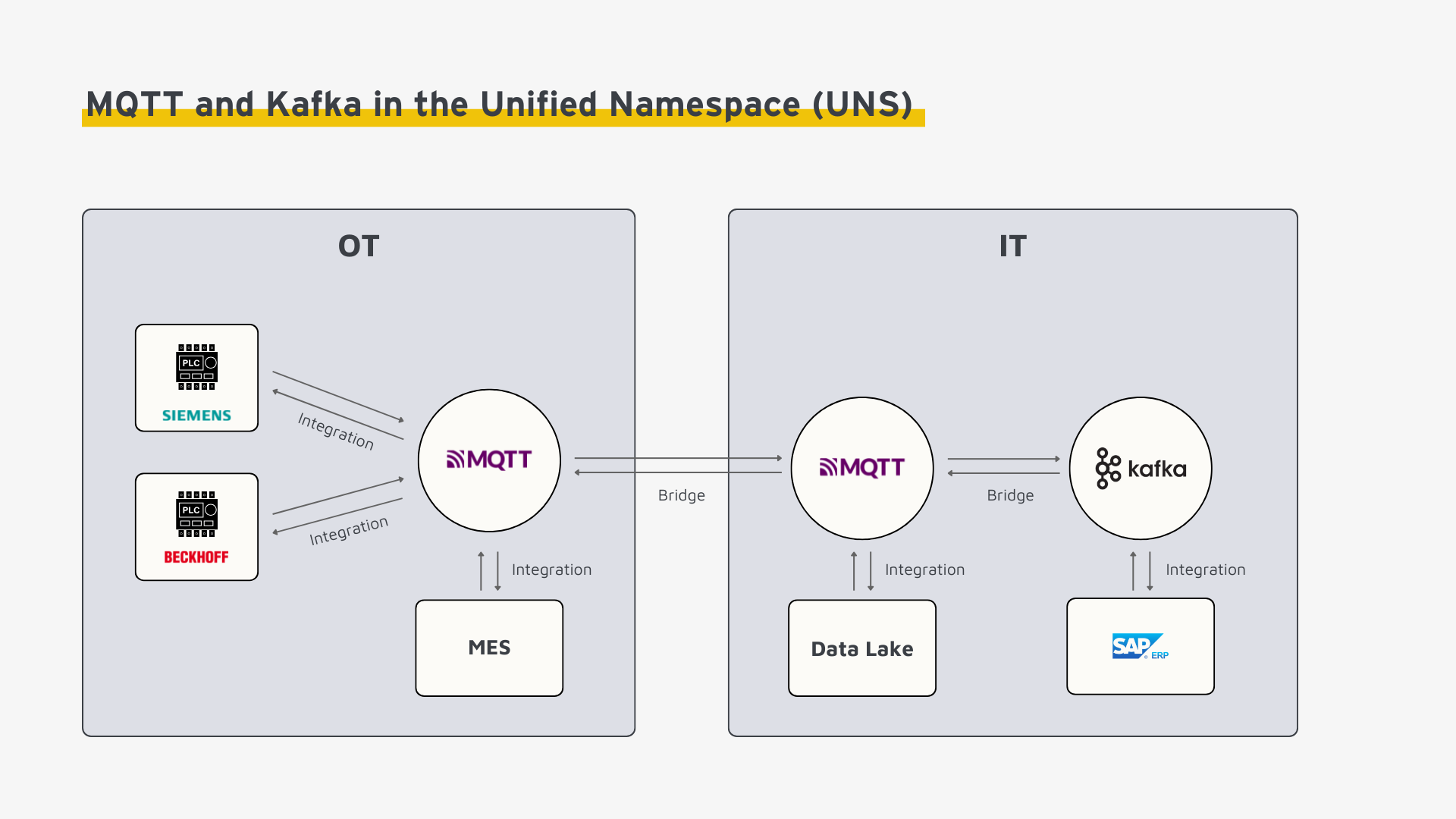
Typische Architektur im Industrial IoT
Ein häufig realisiertes Konzept kombiniert die Stärken beider Technologien, z.B. auf Basis der Unified Namespace (UNS) Architektur wie folgt:
MQTT ist speziell für ressourcenbeschränkte Geräte und industrielle Umgebungen entwickelt. Es eignet sich daher ideal für die Kommunikation von Sensoren, Maschinen und Steuerungen im Werk. In hybriden Edge-to-Cloud-Architekturen übernimmt MQTT eine zentrale Rolle als schlanke und zuverlässige Schnittstelle zur Datenübertragung zwischen OT-Systemen und IT-Anwendungen. Während auf Edge-Geräten kompakte MQTT-Instanzen mit minimalem Ressourcenverbrauch betrieben werden, übernehmen in der Cloud horizontal skalierbare MQTT-Broker die Kommunikation.
Apache Kafka hingegen spielt seine Stärken in der IT-Welt aus – insbesondere in Cloud-Umgebungen und Rechenzentren, in denen große Datenmengen verarbeitet und analysiert werden. Als verteilte Event-Streaming-Plattform ist Kafka für den Aufbau skalierbarer Datenarchitekturen, die Echtzeitverarbeitung, persistente Speicherung und Verteilung von Event-Daten ermöglichen, hervorragend geeignet.
Fazit
Die Frage ob „MQTT oder Kafka“ lässt sich anhand der Anforderungen im Anwendungsfall beantworten. Um Kafka gewinnbringend einzusetzen, sollten die Skalierungsvorteile den Mehraufwand in Implementierung und Wartung über-kompensieren. In der Praxis werden MQTT und Kafka oft komplementär eingesetzt – zum Beispiel MQTT auf der Edge-Ebene für die Kommunikation mit Industrial IoT-Geräten und Kafka für die Verarbeitung der Datenströme in der Cloud. Beide haben spezifische Stärken und können gemeinsam genutzt werden, um robuste, skalierbare und effiziente Industrial IoT Architekturen zu schaffen.
