
Apache Kafka is a powerful event-streaming platform built for highly scalable architectures. Its architecture was designed with throughput, scalability, and durability of data streams in mind. These very properties are why many projects face the same question: is Kafka or MQTT the better choice for Industrial IoT? This article answers that question, comparing the two technologies across their use cases, strengths, and limitations.
If you’d also like to weigh AMQP and NATS into the decision, our Message Broker Comparison in IIoT offers a complete side-by-side look at all four protocols.
The Emergence of Kafka: From LinkedIn to Open Source
Kafka was originally developed by LinkedIn and later handed over to the Apache Software Foundation as an open source project. It was originally designed to address LinkedIn’s challenges in processing large amounts of data and providing real-time data to the rapidly growing network. The name “Kafka” was chosen after the famous Czech writer Franz Kafka. This reflects the objective of robust and error-free data transmission in a complex and often chaotically distributed environment.
Event-based Communication
Kafka minimizes bandwidth usage by moving from a conventional “poll-response” behavior (such as the OPC UA client-server architecture) to an event-based “publish-subscribe” behavior. Event-based means a data consumer waits for data changes (instead of polling it cyclically). This enables real-time, event-driven communication between devices and applications within the organization and beyond. Further information can be found here.

Advantages and Disadvantages of Kafka
Apache Kafka offers several key advantages in industrial environments and enterprise-wide applications:
- Processing large amounts of data: Kafka can handle huge amounts of data effectively and offers high throughput rates. This is particularly helpful when processing large data streams in enterprises.
- Persistence and fault tolerance: Kafka stores data permanently and replicates it across multiple brokers. This means that message loss is largely ruled out, even in the event of server failures. In addition, data can be read by consumer systems at any time (replay functionality).
- High scalability and performance: Kafka is designed for highly parallel data streams and easily processes millions of messages per second. Thanks to horizontal scaling (more brokers = more performance), latency remains low even with increasing data volumes, while throughput remains consistently high. This makes Kafka ideal for processing large volumes of data in real time – for example in streaming applications.
Despite its strengths, Apache Kafka also poses several challenges, especially in industrial environments:
- High infrastructure and operating costs: Kafka is a complex system that requires the operation of several components (Broker, ZooKeeper/KRaft, Schema Registry, etc.). The setup, monitoring and maintenance require specialized know-how and cause considerable administrative effort.
- High resource consumption: Kafka is built for high data throughput and persistent storage, which demands significant CPU, RAM, and disk capacity. Especially in scenarios with large data volumes, numerous partitions, or extended retention periods, this can result in a highly resource-intensive system landscape.
- Limited suitability for small or sporadic data volumes: Kafka is optimized for high throughput rates and continuous data streams. In scenarios with small messages or irregular data intervals, Kafka is usually oversized and inefficient. For example, transmitting a temperature value every few seconds generates unnecessary overhead compared to lightweight protocols like MQTT.
Kafka in Industrial IoT
Manufacturing companies use Kafka particularly in environments with high scaling requirements, to transfer data streams between systems and applications. The platform ensures that data is forwarded to all subscribers in a reliable and fault-tolerant manner. Kafka therefore gains importance in the following use cases:
- Communication across different layers: Kafka is increasingly being used by large manufacturing companies (e.g. automotive OEMs) as a communication protocol for the Enterprise and Connected World layer of RAMI 4.0. The aim is to minimize integration costs and increase the scalability of system architectures.
- Unified Namespace (UNS): The UNS architecture provides a centralized, non-hierarchical structure in which all factory data is made accessible through a standardized naming convention and data model, typically via a central message broker. Apache Kafka supports this paradigm by allowing data producers to continuously publish data streams to the broker. Following the “publish once, distribute everywhere” principle, this enables any number of systems and applications to consume the same data in real time. You can find more information about UNS in our blog.
")
MQTT or Kafka: Which is the Better Fit?
MQTT and Apache Kafka are both well-established technologies for data transmission and processing, each built on a broker-based publish/subscribe model. Both enable efficient data exchange between distributed systems and components. However, they differ significantly in their architectural design, performance characteristics, and ideal use cases. Thus, making the right choice highly dependent on the specific requirements of your Industrial IoT application.
What are the Differences?
MQTT and Kafka differ significantly in terms of performance and typical areas of application.
- Throughput and latency:
- MQTT: Offers lower latency and is ideal for use cases where fast delivery of many clients is critical.
- Kafka: Kafka is optimized for high throughput rates. However, this is often achieved through batching, which increases message latency compared to MQTT.
- Data storage:
- MQTT: Is primarily designed to transmit messages with low latency and does not offer any functions for long-term data storage.
- Kafka: Provides robust data storage capabilities and can retain messages for extended periods of time (configurable) for reprocessing.
- Delivery guarantees for messages:
- MQTT: Users configure the delivery guarantee per use case via Quality of Service (QoS) levels – “at most once” (QoS 0, fire-and-forget), “at least once” (QoS 1, possible duplicates) or “exactly once” (QoS 2, no duplicates or losses).
- Kafka: Uses at-least-once semantics by default, i.e. messages are delivered at least once (duplicates are possible). Exactly-once semantics can only be achieved with additional configuration effort on the producer and consumer side.
- Fault tolerance and recovery:
- MQTT: Has mechanisms for message acknowledgement, but no native support for “replays” for later recovery.
- Kafka: Strong ability to recover data after a failure thanks to persistent storage architecture and “replay” functionality.
- Implementation and maintenance effort
- MQTT: The implementation, configuration, management and monitoring of MQTT brokers are relatively simple.
- Kafka: Kafka is significantly more complicated and complex. Topics such as cluster management, partitioning, replication and monitoring require in-depth expertise and a dedicated infrastructure.
- Resource requirements:
- MQTT: Designed to conserve resources and is ideal for use on hardware with limited computing power, memory and bandwidth – especially on the edge.
- Kafka: Offers high performance and scalability, but requires significantly more system resources. This makes Kafka unsuitable for direct use on resource-limited edge hardware.
Summary of the Differences
| Aspect | MQTT | Kafka |
|---|---|---|
| Throughput and latency | Low latency, ideal for time-critical message transmission. | High throughput due to batching, but higher latency than MQTT. |
| Data storage | No native long-term storage, focus on real-time transmission. | Persistent storage with configurable retention and replay. |
| Delivery guarantees | QoS levels configurable: 0 (at most once), 1 (at least once), 2 (exactly once). | By default at least once; exactly once only with additional effort. |
| Fault tolerance & recovery | Confirmation possible, but no native support for replay or long-term storage. | High fault tolerance thanks to persistent storage and replay function. |
| Implementation & maintenance | Simple setup, configuration and maintenance. | Complex setup with higher maintenance effort (e.g. cluster management). |
| Resource requirements | Resource-saving, ideal for edge devices with limited performance. | High resource requirements, unsuitable for edge devices. |
What do MQTT and Kafka have in Common?
Despite their differences, MQTT and Apache Kafka have a number of fundamental similarities:
- Data transfer based on publish/subscribe: Both technologies are based on the publish/subscribe model. This means that data producers (publishers) send messages to a central system, while consumers (subscribers) receive targeted messages without being directly connected to the sender. This decoupled communication enables a flexible and scalable architecture.
- Open standards & broad support: MQTT and Kafka are open source – both are supported by a large community as well as numerous industrial and cloud-based platforms. This enables broad integration into existing systems.
- Scalability and redundancy: Both technologies are designed for high-availability operation. Both MQTT Broker and Kafka Cluster can be scaled horizontally and operated redundantly to ensure reliability and continuous data availability.
- Distributed systems: Both technologies support distributed systems and can be implemented in environments with multiple servers and clients.
- Reliable data transmission: Both Kafka and MQTT offer mechanisms to guarantee data transmission, although the implementation and guarantees are different.
MQTT vs. Kafka: Typical Areas of Application in Industrial IoT
In Industrial IoT, MQTT and Apache Kafka differ not only in their technological basis, but above all in their typical area of application within IT/OT architectures.
IT/OT Requirements in Industrial IoT
Depending on the application level – OT, IT or cross-IT/OT – there are different requirements for an IIoT data architecture. The following overview shows which requirements MQTT and Kafka fulfill particularly well:
| Relevance | Requirement | MQTT | Kafka |
|---|---|---|---|
| OT | Edge capability (resource-saving operation) | ✅ | |
| OT | Lightweight protocol | ✅ | |
| OT | Latency-optimized data transmission | ✅ | |
| OT | Scalable for many clients with a small payload | ✅ | |
| OT | Easy implementation & maintenance | ✅ | |
| IT/OT | Event-based communication (Publish/Subscribe) | ✅ | ✅ |
| IT/OT | Reliable data transmission | ✅ | ✅ |
| IT/OT | OT/IT security (TLS, authentication, ACLs) | ✅ | ✅ |
| IT/OT | Redundancy (highly available operation) | ✅ | ✅ |
| IT/OT | Open source technology with broad support | ✅ | ✅ |
| IT | Scalable processing of large amounts of data | ✅ | |
| IT | Persistent storage & replay capability | ✅ |
Choosing the Right Broker for Your Use Case
In industrial environments, MQTT and Kafka each offer clear technical advantages—depending on the use case. OT-level communication, mobile applications, and low-power sensor networks particularly benefit from MQTT’s lightweight protocol design.
1. Lightweight, Low-Latency OT Communication
Examples: PLCs sending cycle times in the 1–10 ms range; Beckhoff/Siemens controllers publishing high-frequency cycle data directly from the control layer.
Why MQTT? Minimal protocol overhead, QoS guarantees, and a footprint suitable for embedded devices.
Why not Kafka? Kafka requires a full producer client at the edge—resource-heavy and without QoS semantics.
2. Bidirectional Communication / Command & Control
Example: Remote parameter changes (e.g., SetSpeed) on a machine.
Why MQTT? Retained messages ensure a machine receives the latest parameter immediately after restart; Last Will signals device failures; lightweight publish/subscribe communication.
Why not Kafka? Consumers only read forward (no concept of “current state”), no retain/state semantics, no QoS or built-in state handling.
Note: For true Command & Control, point-to-point Request/Response patterns (e.g., via i-flow Edge) are often a better fit, as they provide reliable end-to-end acknowledgements—something broker-based communication cannot guarantee.
3. Energy-Efficient or Mobile Devices
Examples: Battery-powered sensors (temperature, vibration), AGVs sending positions and receiving job updates, tablets/wearables experiencing connectivity gaps on the shop floor.
Why MQTT? Designed for low-power and unstable networks; Session Resume for seamless reconnection; QoS levels for reliable delivery; retained messages provide immediate last-known state; Last Will detects device loss.
Why not Kafka? Too heavy for embedded or battery-driven devices; requires persistent TCP connections; lacks QoS, session handling, and store-and-forward capabilities.
4. Highly Scalable Distributed Event Streams for Big Data & Analytics
Example: KPI and OEE calculations across 120 factories using streaming event data.
Why Kafka? Horizontal partitioning, massive throughput (GB–TB per day), replay capability for ML/analytics, and seamless integration with stream processing frameworks (Flink, Kafka Streams).
Why not MQTT? MQTT is a transport protocol only—no replay, no partitioning, and no stream processing support.
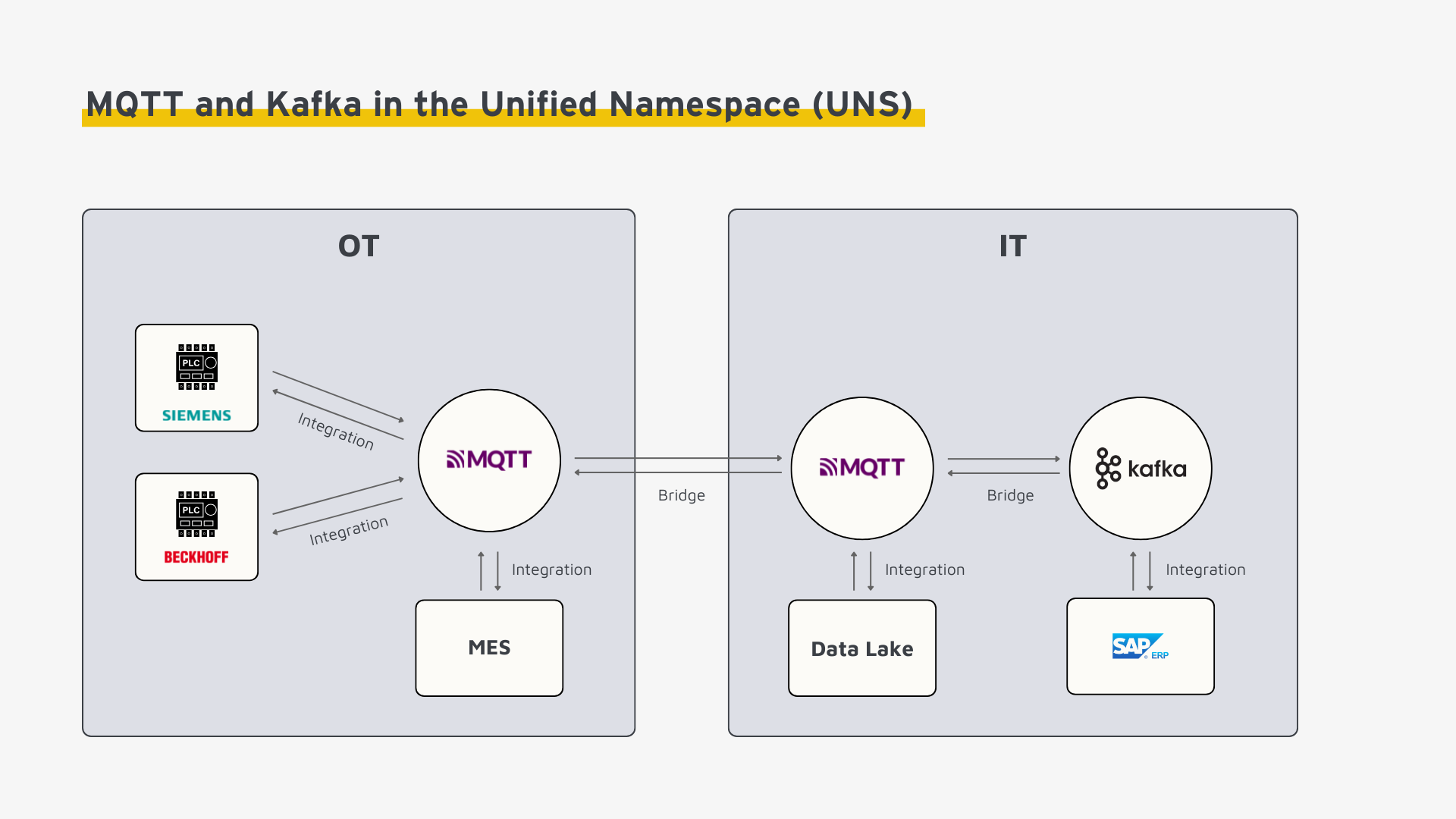
Typical Architecture in Industrial IoT
A widely adopted architecture in the Industrial IoT combines the strengths of both MQTT and Apache Kafka, often within a Unified Namespace (UNS) framework:
MQTT is specifically designed for edge scenarios and industrial environments. Therefore, it excels at enabling reliable communication between sensors, machines, and controllers at the factory level. In hybrid edge-to-cloud architectures, MQTT serves as a lightweight and dependable interface for transmitting data from OT systems to IT applications. On the edge, minimal-footprint MQTT instances run efficiently on limited hardware, while horizontally scalable MQTT brokers in the cloud handle high volumes of incoming data streams.
Apache Kafka, by contrast, is optimized for the IT domain—particularly in cloud infrastructures and data centers where massive data volumes need to be processed and analyzed. As a distributed event streaming platform, Kafka is ideally suited for building scalable, high-throughput data architectures that support real-time analytics, persistent storage, and broad distribution of event data across enterprise systems.
Conclusion
The choice between MQTT and Apache Kafka ultimately depends on the specific requirements of the use case. Kafka offers powerful scalability and performance—but its benefits are only fully realized when they outweigh the added complexity and operational overhead. In many real-world scenarios, the most effective approach is to use both technologies in a complementary fashion: MQTT at the edge for efficient, low-latency communication with industrial IoT devices, and Kafka in the cloud or data center for high-throughput processing, storage, and distribution of data streams. Together, they enable robust, scalable, and future-proof Industrial IoT architectures.
